↑ これは見やすいけど、Rで計算する場合は tidy data じゃないのでちょっと困る。
これを、Rに取り込んで、tidy data に変換する方法。
tidy data と messy data については、多くのサイトで詳しく紹介されているので、ここでは割愛。
整然データとは、1) 個々の変数が1つの列をなす、2) 個々の観測が1つの行をなす、3) 個々の観測の構成単位の類型が1つの表をなす、4) 個々の値が1つのセルをなす、という4つの条件を満たした表型のデータのことであり、構造と意味が合致するという特徴を持つ。R言語などを用いたデータ分析の際には非常に有用な概念である。
データの取り込み
まずは、もらった "Fig044_BlMSA03-2dHipp.xlsx" という名前の xlsx シートの "Score" という名前のシートを取り込む。
# xlsx データの取り込み
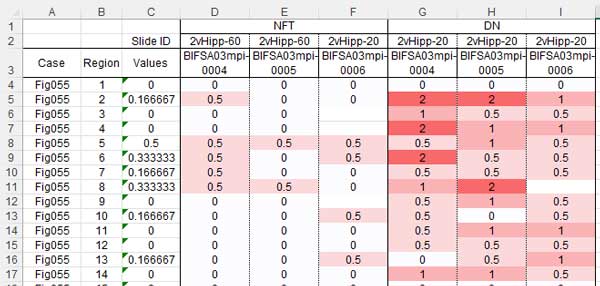
Dat1 <- readxl::read_xlsx("./Data/Fig044_BlMSA03-2dHipp.xlsx", sheet="Score" )取り込んだデータはこんな感じ。
これは、1行目の4-6列目と7-9列目のセルがそれぞれ結合されているので、セルの名前は4列目 (NFT) と7列目 (DN) に宛てがわれ、それ以外の列は "...5", "...6", "...8", "...9" という名前が列名として宛てがわれた、とゆーこと。
tidy data に変換
tidy data に変換する準備
本来は、2行目にあたる文字列を列名にしたいけど、このまま
colnamesで指定してしまうと、同じ名前の列が2つできてしまうのでダメ。
まずは、"BlFSA03mi-0004", "BlFSA03mi-0005", "BlFSA03mi-0005" をそれぞれ "NFT_0004", "NFT_0005", "NFT_0006", "DN_0004", "DN_0005", "DN_0006" という名前に変える。
# sub() で名前を変更
Dat1$NFT <-sub("BlFSA03mpi-", "NFT_", Dat1$NFT)
Dat1$"...5" <-sub("BlFSA03mpi-", "NFT_", Dat1$"...5")
Dat1$"...6" <-sub("BlFSA03mpi-", "NFT_", Dat1$"...6")
Dat1$DN <-sub("BlFSA03mpi-", "DN_", Dat1$DN)
Dat1$"...8" <-sub("BlFSA03mpi-", "DN_", Dat1$"...8")
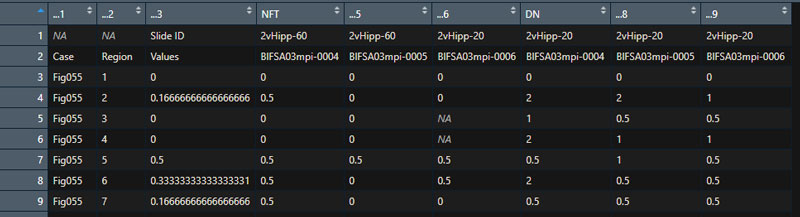
Dat1$"...9" <-sub("BlFSA03mpi-", "DN_", Dat1$"...9")それから、変更した名前を列名として指定し、
# colnames() で列名を指定
colnames(Dat1) <- Dat1[2,]要らなくなった1行目と2行目を削除して、
# 1行目と2行目を削除
Dat1 <- Dat1[-(1:2),]目的通りの列名が宛てがわれた。
縦型の tidy data に変換する:gather()
で、いよいよ tidy data に変換する。
使用するコードは
tidyr::gather()。
gather(データ名, key="新たに追加する列名", value="データ値", 縦に並べるべき変数1, 2, 3...)という感じで使う。
# gather 関数で縦型に構造を変換する
gather(Dat1, key="CaseID", value="Score", NFT_0004, NFT_0005, NFT_0006, DN_0004, DN_0005, DN_0006)こんな感じに、縦型の tidy data に変換できた。
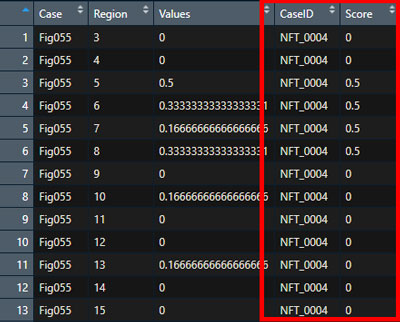
この時点で、"Case" の value が "Fig055" じゃなくて "Fig044" にしないといけないことに気づいたので、gsub で置換。
# Fig055 を Fig044 に変更
Dat1$Case <- gsub("Fig055", "Fig044", Dat1$Case)横型のデータに変換
横型のデータに変換する準備
で、今回の場合、"0004", "0005", "0006" をそれぞれ variable にしたかったので、その準備をしていく。
まずは、
dyplr::mutate()で、NFT/DN の 情報が入った列を作る(列名は "Path" とした)。
# mutate で列の追加、substr で、CaseIDの列の、1-3番目の文字を切り出し
Dat1 <- Dat1 %>%
mutate(Dat1, Path=substr(Dat1$CaseID, 1, 3))
# gsub で "_" を消去
Dat1$Path <- gsub('_', '', Dat1$Path)
# select で列の並べ替え
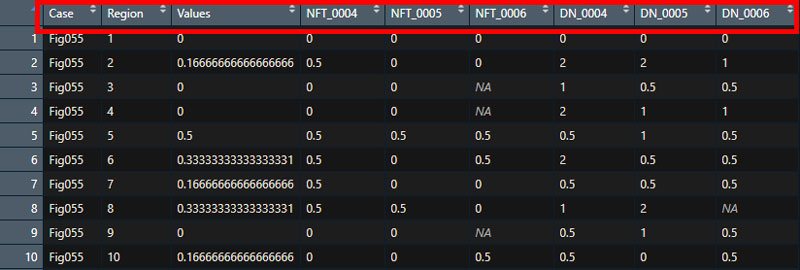
Dat1 <- select(Dat1, Case, Region, Values, Path, CaseID, Score)
# "_" を削除
Dat1$Path <- gsub('_','',Dat1$Path)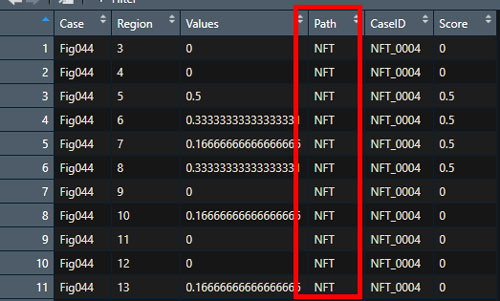
下図のように、"CaseID" の列の左側に "Path" という名前の列ができ、"DaseID" の頭文字が "NFT_" だったら "NFT"、"DN_" だったら "DN" という値が入るようになった。
そしてCaseIDの列は、"NFT_0004" → "0004"、"DN_0004" → "0004" というように、最初の3-4文字を消去し、
# gsub で NFT_ と DN_ を削除。
Dat1$CaseID <- gsub('DN_', '' , Dat1$CaseID) Dat1$CaseID <- gsub('NFT_', '' , Dat1$CaseID)
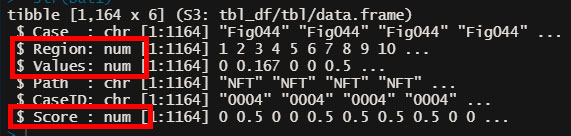
データを spread する前に、計算に必要なデータ型を "numeric" に変換しておく。
# "Score", "Values", "Region" のデータ型を "numeric" に変換
Dat1$Score <- as.numeric(Dat1$Score)
Dat1$Values <- as.numeric(Dat1$Values)
Dat1$Region <- as.numeric(Dat1$Region)
str()で確認したら無事に変換できていた。
横型のデータ構造に変換する: spread()
ここまでできたらOK。
ただ、ここまで tidy だと逆に私がわかりにくいので、部分的に横型に変換。
使用するコードは
tidyr::spread。
spread(データ名, key="新たに追加する列名", value="データ値)という形で使用する。
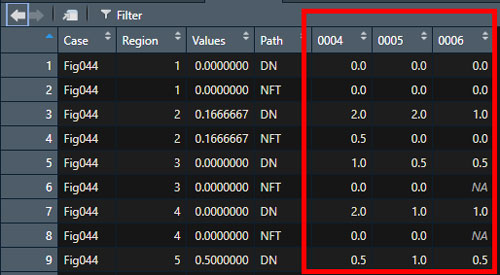
# spread で横型のデータに変換
Dat1 <- spread(Dat1, key=CaseID, value=Score)こんな形の横長データに変換された。
おまけ
このデータから "NFT" と "DN" の各 region の平均値が入った csv ファイルをヒートマップように出力したかったので、下記のようにそれぞれ抽出して出力。
# NFT の平均値のcsvを出力
Dat_NFT <- filter(Dat1, Path=='NFT' ) %>%
mutate(Values = rowMeans(.[,5:7], na.rm = T)) %>%
select(Case, Region, Values) %>%
write.csv("Fig044_Heatmap_NFT.csv", row.names = FALSE)
# DN の平均値のcsvを出力
Dat_DN <- filter(Dat1, Path=='DN' ) %>%
mutate(Values = rowMeans(.[,5:7], na.rm = T)) %>%
select(Case, Region, Values) %>%
write.csv("Fig044_Heatmap_DN.csv", row.names = FALSE)
行方向の平均値の出し方は下記参照。
列A、列B、列C...の各行毎に平均値を出して、それぞれ新しい列に結果を追加する方法3つ。 個人の練習も兼ねて前後の工程も記載しているので、あしからず。 事前準備 データの取り込み 人からもらった、とあるデータを取り込む …
csvで出力するとき、
now.names = TRUEにしておくと、行番号がA列に入ってしまい、アプリに取り込むとバグるので、
now.names = FALSEにして、行番号がA列に入ってこないようにする。