データ整理をしていると、データが抜けていて欠損値になっている事がある。
この時の対処方法いろいろ。
前処理:空欄を NA に置き換えてデータをインポートする
例えば、下記のようなデータがあって、いくつか空欄がある。
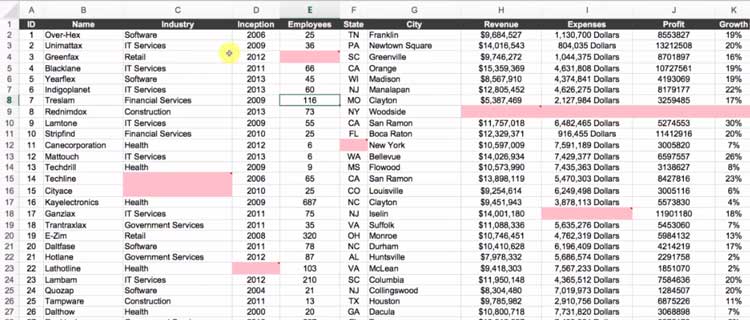
これをRに取り込むと、
Dat <- read.csv("Data.csv")エクセルのデータを R にインポートする方法。 csv ファイル エクセルデータを csv ファイルに保存してインポートするのが最も一般的。 CSV ファイルとは CSV ファイルは、「comma Separated V …
空欄部分は時々空欄のまま、時々"NA"として認識される。
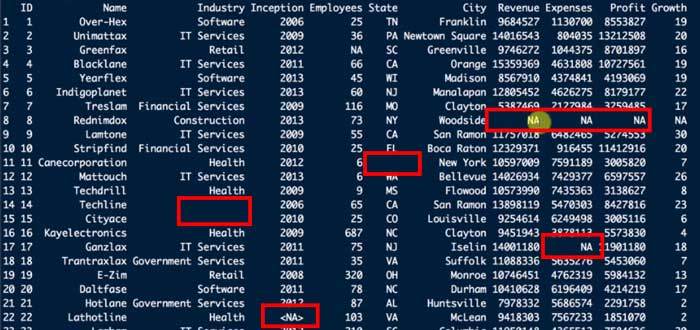
このデータフレームでそのまま!complete.cases()を使ってNAのデータを抽出しようとしても、下記のように、たまたま<NA>に認識された6行のみが抽出される。

これは、そのまま「空欄」として認識されたウェルは欠損値として認識されていないから。
これを避けるためには、データのインポートの段階で、空欄""をNAで置換しておくと良い。
Dat <- read.csv("Data.csv", na.strings=c("")) # 空欄部分を<NA>に置き換えるそして、Dat[!complete.cases(Dat),]で選出すると、
Dat2 <- Dat[!complete.cases(Dat),]最初の段階では選出されなかった行も<NA>を含む行として認識され、抽出された。
条件に合った行を、NAのある行が入らないように抽出する:「which()」
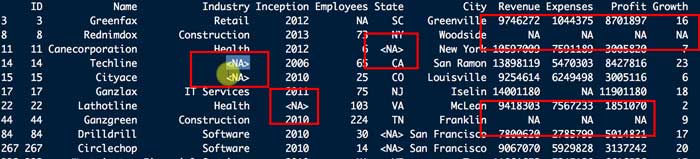
例えば、上記データの中から、"Revenue" が "9746272" の行を抽出すると、
Dat[Dat$Revenue == 9746272,]下図のように、1行は求めたい "Revenue == "0746272" だけど、その下に、<NA>という謎の2行がついてくる。
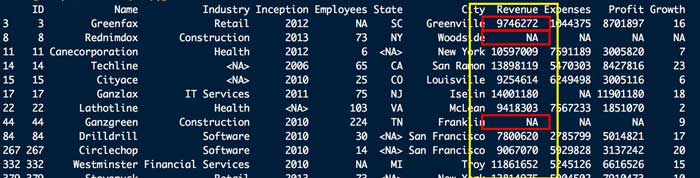
これはなんでかというと、参照列の "Revenue" に <NA> が入っていると、Rはこれも抽出してくるから。

Rは1行目から "TRUE" or "False" で検証していって、3行目は "TRUE" だから選出。
もう少し降りて 8行目と44行目に "NA" があるのを見つけると、それも選出する、という感じ。
これを防ぎ、本当にほしいデータだけ抽出したい場合には、which() 関数を挟む。
Dat[which(Dat$Revenue == 9746272),]which()関数は、"TRUE" のデータだけを選出する関数。
これを使うと、下記のようにほしいデータだけ抽出できる。
この方法は、「ある条件に合った行を抽出したい」時、「NA」行が入りこまないようにするために使う。
で、次からは、「とにかくNAのある行を除く/NAのある行のみを抽出する」場合に使う方法。
任意の列で、NAの行を除いて抽出する
[ ] を使って抽出する
[ ] を使って抽出する方法を2つ書き留めておく。
一つは is.na()を使う方法、もう一つはcomplete.cases()を使う方法。
「!is.na()」 を使って抽出する
is.na()は、NAかどうかを問う関数。
この前に「~じゃない」演算子である「!」を置くと、「NAじゃない」データを問う関数となる。
例えば、Revenueの列が「NAじゃない」行を抽出する場合、
Dat <- Dat[!is.na(Dat$Revenue),]で抽出される。
「complete.cases()」を使って抽出する
complete.casesは、「NAじゃないデータ」を抽出する時に使う。
例えば、Revenueの列が「NAじゃない」列を抽出する場合、
Dat <- Dat[complete.cases(Dat$Revenue),]で抽出される。
※ ブラケット[ ]を使う場合、要素を揃えないといけない(相手がベクターならこっちもベクター)ので、「データ全体でNAを省く」というような使い方はできない。
[ ] の使い方は下記参照。
Vector、Matrix、DataFrame、List etc. から [] (square brackets) を使って特定の要素へアクセスする方法。 ベクトル (Vector) の場合 Vectorを作る。 v & …
「subset()」を使って抽出する
「抽出する」関数のsubset()と、!is.na()/complete.cases()との組み合わせも書き留めておく。
subset(データ, 条件)という形で使う。
「!is.na()」を使って抽出する
例えば、Revenueの列が「NAじゃない」列を抽出する場合、
Dat <- subset(Dat, !is.na(Dat$Revenue))で抽出される。
「complete.cases()」を使って抽出する
complete.cases()を使って、Revenueの列が「NAじゃない」列を抽出する場合、
Dat <- subset(Dat, complete.cases(Dat$Revenue))で抽出される。
データフレーム全体でNAが一つでもある行を除いて抽出する
subset()とcomplete.cases()の組み合わせの場合は、もう一つ、「データフレーム全体でNAが一つでもある行を除く」という方法もできる。
Dat <- subset(Dat, complete.cases(Dat))任意の列でNAを含む行のみを抽出する
例えば "Revenue" が <NA> の行を抽出したい場合、
Dat[Dat$Expenses == NA,]としちゃうと、下記にように、見事に全てがNAになって返ってくる。

これはなんでかというと、RはNAを他のTRUE/FALSEと比較検討できないから。
これを避ける為に、さっき使ったcomplete.cases()や!is.na()の逆Ver.を使って抽出する。
[ ] を使って抽出する
さっきの逆ヴァージョン。
「!is.na()」 を使って抽出する
例えば、Expenseの列でNAがある行を抽出したい時、さっきの!is.na()の逆で、is.na()を挟むと良い。
Dat[is.na(Dat$Expenses),]
目的通り、"Expenses" が <NA> の行だけ抽出できた。
「complete.cases()」を使って抽出する
complete.cases()を使って、、Expensesの列が「NA」の列を抽出する場合、さっきの反対で「!」を関数の前につける。
Dat <- Dat[!complete.cases(Dat$Expenses),]で抽出される。
「subset()」を使って抽出する
これもさっきの反対。
「is.na()」を使って抽出する
例えば、Expensesの列が「NA」の行を抽出する場合、
Dat <- subset(Dat, is.na(Dat$Expenses))で抽出される。
「!complete.cases()」を使って抽出する
complete.cases()を使って、Expensesの列が「NA」の行を抽出する場合、「!」をつけて、
Dat <- subset(Dat, !complete.cases(Dat$Expenses))で抽出される。
データフレーム全体でNAが一つでもある行を抽出する
「どこかにNAを持つ行」を抽出する場合は、subset()とcomplete.cases()の組み合わせで。
Dat <- subset(Dat, !complete.cases(Dat))
・
・
・
演算子の使い方は下記参照。
演算子等の覚え書き。 論理演算子 論理演算子 左片は右辺より大きい = 左片は右辺以上 == 等しい != 等しくない ! 否定 | 両辺のど …
ブラケット [ ] の使い方は下記参照。
Vector、Matrix、DataFrame、List etc. から [] (square brackets) を使って特定の要素へアクセスする方法。 ベクトル (Vector) の場合 Vectorを作る。 v & …
・
・
・
次回は、欠損値の削除/補完方法について記載予定。
References

![]()