エクセルのデータ etc. を R にインポートする方法。
csv ファイル etc. の取り込み
エクセルデータは基本 csv ファイルで保存し、R に取り込む。
CSV ファイルは、「comma Separated Value」の略。
カンマ(,)で区切った値、という意味。
csvファイルは相互性が高く、Excel、メモ帳、メールソフト、データベースなどほとんどのソフトに取り込んで、閲覧・編集することが可能。
Excel を CSV ファイルで保存するには、保存時に *.csv 拡張子を選択する。
このページでは取り込み方法をいくつか書き留めているが、基本的には、インポート②の「"readr パッケージ: read_csv"」で取り込んでいる。
CSV ファイルのインポート①: R 標準関数 read.csv
1.作業ディレクトリの場所を確認。
デフォルトの作業ディレクトリは、上の階層にある。 この作業ディレクトリのデフォルトを任意の場所に変更したい場合。 デフォルトのディレクトリを変更する方法 1. RStudioを開く 2. Tools -> Glo …

getwd()
[1] "D:/R/R directory/Test2.CSV ファイルを作業ディレクトリと同じ場所に保存。
3.read.csv でインポート。
Dat1 <- read.csv("ファイル名.csv")CSV ファイルのインポート②: readr パッケージ read_csv
Hadley氏が作製したパッケージ。
下記のような利点が満載なので、普段はこの方法を使っている。
- 処理速度が速い(Rの標準関数の10倍速い)。
- 省メモリ。
- 指定した列だけ読み込む事も可能。
- 読み込まれたデータは tibble 型のオブジェクトとして保存される(R 標準関数ではデータフレーム型)。
- 文字列データを勝手に因子型に変換しない(stringsAsFactors = FALSEが常に指定されている状態)。
- 列名を勝手に(X.1、X.2、X.3 などのように)変換しない。
tidyverse のインストール と 読み込み
readr パッケージは tidyverse パッケージの中に入っている。
install.packages(tidyverse)library(tidyverse)
read_csv()
csv ファイルは、"read_csv()" で取り込む。
Dat1 <- read_csv("ファイル名.csv")read_tsv()
tsv ファイルは、"read_tsv()" で取り込む。
Dat1 <- read_tsv("ファイル名.csv")read_delim()
csv, tsv 含め、区切り文字を指定して、ファイルからデータを読み込むときに、"read_delim()" で取り込む。
read_delim(file,
delim,
quote = '\"',
escape_backslash = TRUE,
escape_double = FALSE,
na = "NA",
col_names = TRUE,
col_types = NULL,
skip = 0,
n_max = -1,
progress = interactive())| パラメータ | デフォルト値 | 解説 |
|---|---|---|
| file | ファイルパス、コネクション、リテラルデータを指定。 gz、bz2、xz、zipは自動解凍る。 http:// 、https://、ftp://、ftps://はdownload |
|
| delim | 区切り文字 | |
| quote | \" | quote string |
| escape_backslash | TRUE | |
| escape_double | FALSE | |
| na | NA | 値がない場合に入れる文字 |
| col_names | TRUE | TRUE: ヘッダー行を列名とする。 FALSE: 順に番号振り。 列名に使用するvector。 |
| col_types | NULL | デフォルトの列クラスを上書きする。 |
| skip | 0 | スキップする行数を指定。 |
| n_max | -1 | 読み込む最大行を指定。 |
| progress | interactive() | 推定ロード時間が5秒以上の場合はプログレスバーを表示する。 FALSEを指定すると非表示。 |
CSV ファイルのインポート③: クリップボードにコピーして取り込む方法
ちょっとした解析だったら、クリップボードにコピーして取り込むのも便利。
1.エクセルの中で、取り込みたい内容を選択し、Ctrl + C でコピー。
2.R に取り込む。
Dat1 <- read.table("clipboard", header = TRUE)ヘッダー(列のタイトル)がある場合は、header = TRUE、
ない場合は header = FALSE とする。
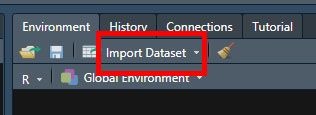
CSV ファイルのインポート④: 右側のペインの "Environment → import Dataset" を使う場合
データ名が長くて面倒…とか、ミススペルが困る…とかいう場合は、右側のペインにある "Environment" から "Import Dataset" をクリックして、マウス操作でインポートすることもできる。
"Import Dataset" をクリックすると、
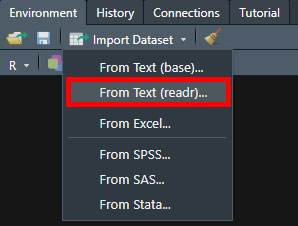
どの形式で取り込むかを選択できる。
csvファイルの場合は "From Text (readr)..." を選択。xlsxファイルの場合は、"From Excel..."を選択。
:
下記のような画面が出てくる。右上の "Browse'..."を押すと、ファイル選択画面が開くので、そこから目的のファイルを選択する。

すると、
- 左上のFile/URLにインポートするファイルの場所
- 真ん中にデータ表示
- 右下にコードのプレビュー
が表示される。
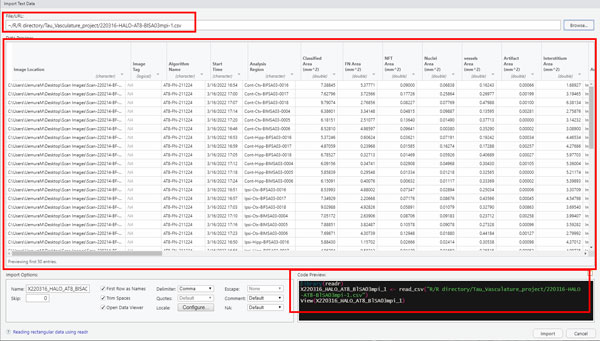
左下のインポートオプションで色々設定できるが、特に変更したくなかったら、そのまま右下の "Import" をクリック。
データがインポートされる。
xlsx ファイルの取り込み
人からもらったExcel ファイル(*.xlsx)をそのまま取り込む場合、readxl 関数を使う。
readxl パッケージのインストールと読み込み
reaxl パッケージも tidyverse パッケージの中に入っている。
install.packages(tidyverse)library(tidyverse)
xlsx ファイルのインポート
read_xlsx で読み込む。
その際、下記etc.を指定できる。
- sheet : 取り込みたいシート
- guess_max : 大まかな全体のセル数
- range : 取り込みたいセルの範囲
Dat1 <- readxl::read_xlsx("ファイル名.xlsx", sheet = "Sheet2" guess_max=2500, range="A1:G322")csv ファイルであればシートの概念がないためオプションでsheetを指定する必要はないが、Excel ファイルの場合はいくつかシートがあって、そのうちのどれかを読み込みたい場合がある。
その場合は、sheet = "Sheet名" で指定できる。
また、同じシート内でも、range = "範囲" で読み込みたいセルの指定ができる。
絶対パスと相対パスについて
上記、csvファイルやxlsxファイルを取り込む際、データが同じフォルダにあったら"ファイル名.csv" etc.だけでいいけど、ファイルが別の場所にある場合は、絶対パスや相対パスで場所を指定する。
絶対パス
場所を1番上の階層から全部書いていく。
Dat1 <- read_csv("D:/R/R directory/R_example/Data/example.csv")
パスを知る方法は下記参照。
エクスプローラー内のファイル名とその場所をまとめてコピーし、メール等に貼り付ける方法。 1.パスをコピーしたいフォルダー or ファイルを選択 2.「Shift + 右クリック」で、「copy as path」の表示が現 …
相対パス
ある程度まで作業ディレクトリと共通の場所があれば、作業ディレクトリのフォルダから参照してパスを指定することもできる。
Dat1 <- read_csv("./Data/example.csv")./は、"同じフォルダ" を指す。
../は、"1個上のフォルダ" を指す。
データのインポート後に行う作業
データを取り込んだら、そのデータの内容を確認する。
欠損値の確認や要素を確認し、以降、データハンドリングしやすいように、適宜修正していく。
2. 先頭の10行を確認「head()」
> head(Dat1,10)

3. 末尾も確認「tail()」
行数を指定しなければ、6行になる。
> tail(Dat1)

4. データの構造を確認「str()」
> str(Dat1)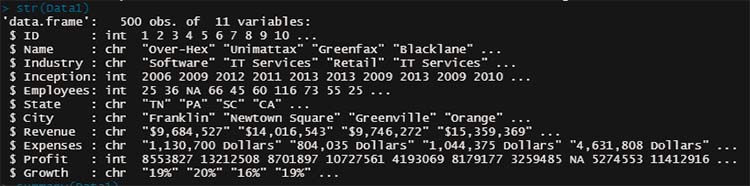
5. データのサマリーを確認「summary()」
> summary(Dat1)