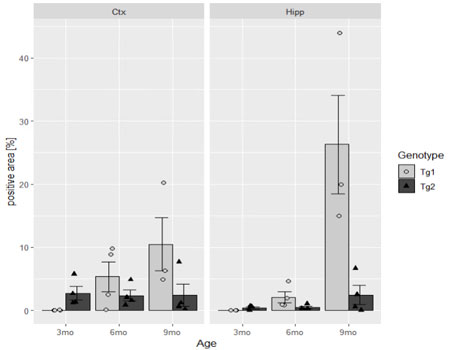
2つのデータフレームを結合するときには、dplyr::join()関数を使う。
join()関数は、dplyrパッケージの関数なので、まずはdplyrパッケージをインストールして読み込む必要がある。
install.packages("dplyr")
library(dplyr)ただし、join()という関数自体はdplyrには存在せず、inner_join()、left_join()、right_join()、full_join()、semi_join()、anti_join()の6つの関数が用意されている。
この中で私がよく使うのは、left_join()。
それぞれの関数の動作は以下の通り。
dplyrのjoin関数の一覧
dplyrには、6つの主なjoin関数がある。
| 関数名 | 動作 | 説明 |
|---|---|---|
inner_join() |
内部結合 (共通する行のみ) | 両方のデータフレームに共通するキーで行を結合 |
left_join() |
左外部結合 (左の全行) | 左のデータフレームのすべての行を含む結合 |
right_join() |
右外部結合 (右の全行) | 右のデータフレームのすべての行を含む結合 |
full_join() |
完全結合 (両方の全行) | 両方のデータフレームのすべての行を含む |
semi_join() |
半結合 (左の行を抽出) | 左のデータフレームの行のうち、右のデータに一致する行だけを返す |
anti_join() |
反結合 (不一致の行) | 左のデータフレームの行のうち、右のデータに一致しない行だけを返す |
inner_join()(内部結合)
- 共通する行のみ結合する。
- 両方のデータフレームに共通するキーを基準にして行を結合。
使用例
library(dplyr)
df1 <- data.frame(ID=c(1, 2, 3), Name=c("Alice", "Bob" , "Charlie" ))
df2 <- data.frame(ID=c(2, 3, 4), Score=c(90, 85, 78))
result <- inner_join(df1, df2, by="ID" )
print(result)output
ID Name Score
1 2 Bob 90
2 3 Charlie 85
※ df1とdf2のIDが共通している行だけが結合される。
left_join()(左外部結合)
- 左のデータフレームのすべての行を残し、右のデータフレームを結合。
- 右のデータフレームに一致しない部分は
NAになる。
使用例
result <- left_join(df1, df2, by="ID" )
print(result)output
ID Name Score
1 1 Alice NA
2 2 Bob 90
3 3 Charlie 85※ df1のすべての行が残り、df2に存在しないID=1はScoreがNAになる。
right_join()(右外部結合)
- 右のデータフレームのすべての行を残し、左のデータフレームを結合。
- 左のデータフレームに一致しない部分は
NAになる。
使用例
result <- right_join(df1, df2, by="ID" )
print(result)output
ID Name Score
1 2 Bob 90
2 3 Charlie 85
3 4 NA 78
※ df2のすべての行が残り、df1に存在しないID=4はNameがNAになる。
full_join()(完全結合)
- 両方のデータフレームのすべての行を結合。
- どちらか一方にしか存在しないデータは
NAが入る。
使用例
result <- full_join(df1, df2, by="ID" )
print(result)output
ID Name Score
1 1 Alice NA
2 2 Bob 90
3 3 Charlie 85
4 4 NA 78※ 両方のデータフレームの全行が結合され、ID=1 (df2にない) と ID=4 (df1にない) はそれぞれNAになる。
semi_join()(半結合)
- df1の行のうち、df2のキーに一致する行だけを抽出する。
- 結合しない。df1の列しか残らない。
使用例
result <- semi_join(df1, df2, by="ID" )
print(result)output
ID name
1 2 Bob
2 3 Charlie
※ df1の行の中で、df2にIDがある行だけが抽出される。
anti_join()(反結合)
- df1の行のうち、df2のキーに一致しない行だけを抽出する。
- 結合しない。df1の列しか残らない。
使用例
result <- anti_join(df1, df2, by="ID" )
print(result)output
ID Name
1 1 Alice
※ df1の行の中で、df2にIDがない行 (ID=1) だけが抽出される。
まとめ
それぞれの関数の比較と使い分けは以下の通り。
| 関数名 | 結合の基準 | 動作 | 特徴 |
|---|---|---|---|
inner_join() |
共通部分 | 両方に共通する行のみを結合 | 共通部分だけが残る |
left_join() |
左のデータ優先 | 左のデータは全て残し、右は一致するものだけ | 左が基準 (左外部結合) |
right_join() |
右のデータ優先 | 右のデータは全て残し、左は一致するものだけ | 右が基準 (右外部結合) |
full_join() |
両方のデータ | 両方のすべての行を残す | すべての行が残る |
semi_join() |
左に一致するもの | 左の行を抽出 (共通するキーのみ) | 一致する行だけ残す |
anti_join() |
左に一致しないもの | 左の行を抽出 (一致しないキーのみ) | 一致しない行を抽出 |
どの関数を使えばいいか?
イメージはこんな感じ。
- 共通のデータだけを残したい →
inner_join() - 左のデータを基準に、右の情報も欲しい →
left_join() - 右のデータを基準に、左の情報も欲しい →
right_join() - 両方のすべての行が欲しい →
full_join() - 左のデータのうち、右の条件に一致する行だけ抽出したい →
semi_join() - 左のデータのうち、右の条件に一致しない行だけ抽出したい →
anti_join()
・
・
・
目的に応じて適切な関数を使い分けると、大変便利!
リンク
リンク
リンク
リンク