統計について何もわからないまま研究を始めた頃、最初に覚えた合言葉:パラメトリックで2群比較はt検定、3群以上の比較は分散分析(Analysis of variance, ANOVA)。
・
・
・
とゆーことで、今回はANOVAをRで行う時の覚え書き。
分散分析の前提条件は下記3点。
- N数が十分に多い
- 分散が等しい
- 正規分布
分散はBartlett検定で、正規性はShapiro-wilk検定で。
| カテゴリー変数 | 連続変数 | 生存曲線 | ||||||
|---|---|---|---|---|---|---|---|---|
群の平均値の比較 |
Fisher 正確検定 カイ二乗検定 |
正規性の検定 | シャピロウィルク検定 (Shapiro-wilk test) コルモゴロフ–スミルノフ検定 (Kolmogorov-Smirnov test) リリフォース検定 (Lilliefors test) |
|||||
| 2群 |
分散の検定 | F検定 (F test) |
||||||
| 正規分布 | 対応なし | スチューデントのt検定 (Unpaired t-test) |
||||||
| 対応あり | 対応のあるt検定 (Paired t-test) |
|||||||
| 非正規分布 | 対応なし | マン-ホイットニーのU検定 (Mann-Whitney U test) |
||||||
| 対応あり | ウィルコクソン符号付順位検定 (Wilcoxon signed rank test) |
|||||||
3群以上 |
分散の検定 | バートレット検定(Bartlett test) ルビーン検定(Levene test) |
||||||
| 正規分布 | 対応なし | 分散分析 (factorial ANOVA) |
log-rank 検定 | |||||
| 対応あり | 反復分散分析 (measured ANOVA) |
|||||||
| 非正規分布 | 対応なし | クラスカル・ウォリス検定 (Kruskal-Wallis test) |
||||||
| 対応あり | フリードマン検定 (Friedman test) |
|||||||
| 多変量回帰 | ロジスティック回帰 | 重回帰 | Cox 回帰 | |||||
| 共分散 | 共分散分析(ANCOVA) | |||||||
| 多変量分散 | 多変量共分散分析(MANCOVA) | |||||||
ANCOVA を R で行う方法: 準備
マウスの病理Xの数が、処置A、処置B、処置Cでどう変わるか調べる。
- 目的変数(response variables):病理X
- 説明変数(explanatory variables):処置(A,B,C,D)
パッケージをインストール
"tidyverse" パッケージ
今回の関数を使う前段階のデータ整理で必須(モデルでは使わない)。
install.packages("tidyverse")
library("tidyverse")"car" パッケージ
3番目の手法 "Anova()" で使用。
install.packages("car")
library("car")ANOVA を R で行う方法色々
R で ANOVA を行う用法は、いくつかあり、それぞれ少しずつ異なる。
- aov()
- anova()
- car::Anova()
- oneway.test()
それぞれの関数の違い
大まかな違いは下記のような感じ。
等分散を仮定しているかどうか
- aov(): 等分散を仮定
- anova(): 等分散を仮定
- car::Anova(): 等分散を仮定
- oneway.test(): 等分散を仮定しないウェルチの分散分析
平方和のタイプの選択
平方和のタイプには、Type I~IVまで4種類あり、多くの統計ソフトでは Type III を使用しているらしい。
Rの場合は、
- aov(): Type I
- anova(): Type I
- car::Anova(): Type を選択できる
- oneway.test(): Type I
aov() と anova() の場合、平方和はタイプIとなっており、自由に選択できない。
これに対して、carパッケージのAnovaは、機能の中で平方和のタイプを指定できる。
2元配置以上の分散分析の場合、この平方和の選択で結果が異なる事があるので問題となるが、1元配置分散分析では問題は発生しない。
aov() と anova() の違い
aov は内部に線形モデルのlm関数を含んでおり、1元時配置分散分析で使用。回帰係数、適合値、残渣などを生成する。
lm オブジェクトの拡張のような感じ。
anova() は一般的な関数で、一元配置分散分析で使用する時は、lm()やaov()でモデルを構築し、それをanova()関数に与える。
方法1:aov() を使う
aov() はRの標準パッケージ。
aov(目的変数 ~ 説明変数, data = データフレーム)のような形で使用する。
下記例では、
- 目的変数: Pathology
- 説明変数: Group
- データフレーム: df
として使用した場合
# aov() を使った方法
model <- aov(Pathology ~ Group, data = df)
summary(model)
出力例
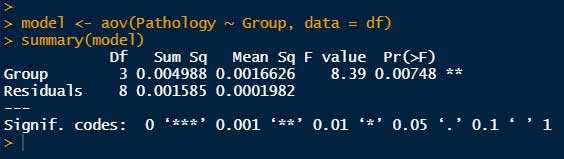
上記 "Pr(>F)" は 0.00748 なので、このデータフレームでは「群間の平均値に差がある」といえる。
方法2:anova() を使う
anova()は一般的な関数。
1元配置分散分析で使用する場合は、まずlm()やaov()でモデルを構築し、それをanova()関数に与える。
anova(lm(目的変数 ~ 説明変数, data = データフレーム))# lm() で線形モデルを構築し、anova()関数に与える
anova(lm(Pathology ~ Group, data = df))
anova(aov(目的変数 ~ 説明変数, data = データフレーム))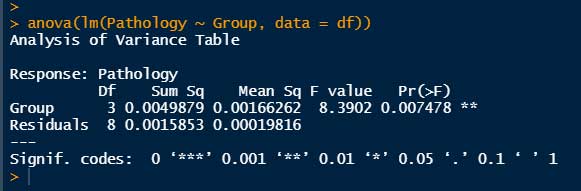
# aov() を使用する場合
anova(aov(Pathology ~ Group, data = df))
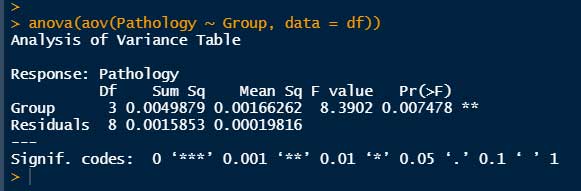
"Pr(>F)" はいずれも 0.00748 となった。
方法3:car::Anova() を使う
carパッケージをインストールすると使える。
aov(), anova() と違って、平方和を指定することができる。
# car::Anova() を使用。Type IIを選択
Anova(lm(Pathology ~ Group, data = df), type = 2)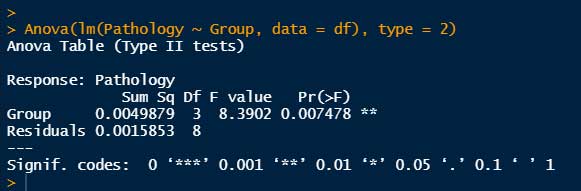
# car::Anova() を使用。Type IIIを選択
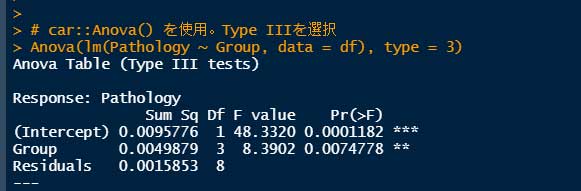
Anova(lm(Pathology ~ Group, data = df), type = 3)
"Pr(>F)" はいずれも 0.00748 となった。
Type III では切片(Intercept)も出てくるが、今回は気にしなくてOK。
方法4:oneway.test() を使う
一元配置分散分析の関数として、oneway.test() も用意されている。
oneway.test(目的変数 ~ 説明変数, data = データフレーム, var.equal = TRUE)オプション "var.equal = TRUE" は各データに等分性を仮定する際に指定するオプションで、通常指定する必要がある。
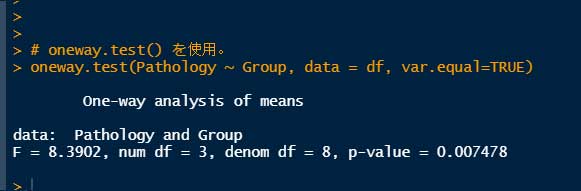
# oneway.test() を使用
oneway.test(Pathology ~ Group, data = df, var.equal=TRUE)
・
・
・
今回はいずれの方法でも、平方和、F値、P値の値が一致した。
変数の名称について
今回、目的変数、説明変数という名称を使用しているけど、下記の言葉群も同じ意味。
- 結果に影響を与える因子の変数
- 説明変数(explanatory variable)
- 独立変数(independent variable)
- 予測変数(predictor variable)
- 1の影響を受けて発生した結果の変数
- 目的変数、応答変数、反応変数(response variable)
- 従属変数(dependent variable)
- 結果変数(outcome variable)
- 基準変数(criterion variable)
- 被説明変数(explained variable)
References
年末年始にやっていた実験データの分析の中で、分散分析を何回も行ったのですが、Rで分散分析をやるときに基本関数では平方和のタイプを選べないんですよね。 簡単な内容なのですが、平方和のタイプを選びながら分析する方法を、メモしておきます。 あわせて、平方和のタイプってそもそもなんだっけ?ってのも、自分のためのメモを兼ねて書いておきます。詳しくは統計の解説書を当たるべきだと思いますが。私は南風原教科書で復習しました(そういえばこれの続編が最近出版されて、いまパラパラと読んでいます)。 心理統計学の基礎―統合的理解のために (有斐閣アルマ)作者:南風原 朝和有斐閣Amazon 重回帰分析の場合 まず、重…
デフォルト設定ではダメ 先日、RでタイプIII(タイプ3)平方和を使う方法についてエントリを書いた直後に、落とし穴があったことに気づいて、まとめたエントリを書こうと思ったんですが、勉強が進んでなくてあまりきちんと理解できておりません。しかし放置しとくのもあれなので、簡単にメモだけしておきます。 前回のエントリでは、Rで分散分析をやるときにタイプⅢの平方和を用いたいのであれば{car}パッケージのAnova()を使うという話をしてたのですが、1つ注意しなければならないことがあります。Rのデフォルトの設定のまま使うと「間違った結果」になります!! 結論としては、Rで アンバランストなデザイン(セル…
分散分析をしようとするとき,思わぬ問題が生じることがあります。 要因計画の各セル内のデータ数が等しいとき(釣り合い型計画のとき)は何の問題もないのですが,何らかの偏りがあるとき(非釣り合い型計画のとき)にはこの問題が生じます。 通常の分散分析の方法で非釣り合い型計画のデータを分析しようとすると,データの投入順序によって計算結果(厳密には,平方和の値)が変わってしまうのです。 この問題に対処するため,平方和についての複数の推定法が考えられてきました。 一般に,タイプⅠ~Ⅳまでの推定法が普及しています。
Rコマンダーで分散分析を行った結果は,他の統計ソフト(例えばSPSSなど)と異なることがあります.1元配置分散分析,反復測定の分散分析(15章)では問題は発生しません.本書では,1元配置分散分析,反復測定の分散分析(15章)しか説明していませんので,以下の問題は2元配置以上(多元配置)の分散分析の場合の補足になります.
I have referred to much of online literature but it is increasing my confusion. Much of the discussion is too technical with terms unbalanced designs and I, II or III factor ANOVA and everything. ...
glm プロシジャにおける TypeI,TypeII および TypeIII 平方和の計算方法について小データを用いて例示 する.また,これらの平方和の相違点について簡単に考察する.
Rによる一元配置分散分析の実行方法とそのオプション群の使い方について.
統計学の「1-5. 説明変数と目的変数」についてのページです。統計WEBの「統計学の時間」では、統計学の基礎から応用までを丁寧に解説しています。大学で学ぶ統計学の基礎レベルである統計検定2級の範囲をほぼ全てカバーする内容となっています。
