文字列から一部だけ切り出して、新しい列を作りたい時。
-
- 列の追加は dplyrパッケージ: mutate
- 文字の切り出しは
- R標準パッケージ: substr or substring
- stringrパッケージ: str_sub
等を使う。
substr
例えば、下記テーブル "Data" の "Group" 列の左から3番目の文字 "F" or "M" を切り出して、"Sex" という列を新たに作りたい場合。
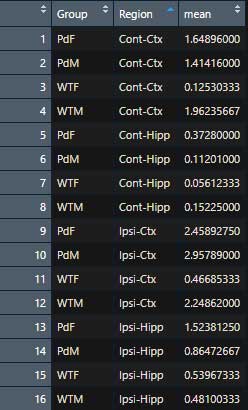
mutate(Data, Sex=substring(Group,3,3))とする。
- 第1因数:対象文字列
- 第2因数:開始位置(左から何番目から開始するか)
- 第3因数:終了位置(左から何番目で終了するか)
※ 1文字目の位置は、他のプログラミング言語では「0」だけど、R言語では見たまま「1」となる。
dplyr::select(Data,Sex,everything())で、"Sex" の列を再左部に持っていくと、目的の列が左側に追加される。
stringr::str_sub
上記R標準パッケージでもいいけど、文字列操作は Hadley氏作製の stringr パッケージで完結した方が便利。
- 処理速度が速い。
- 関数が全て "str_" で始まる。
- パイプ(%>%)で連鎖しやすい。
- R標準にはない機能も色々追加されている。
例えば、stringr::str_sub だと、"末尾から数えて何番目" などの指定もできる。
stringr パッケージは tidyverse パッケージの中に入っているので、tidyverse をインストールしておけば使える。
install.packages(tidyverse)library(tidyverse)
末尾から数える場合
stringr パッケージの
str_sub関数を使うと、末尾から数えた部分文字を抽出できる。
正の整数で位置を指定すると、"前から数えて何番目" となるけど、"後ろから数えて何番目" と指定したい場合は、負の整数(-1, -2 etc.)を使う。
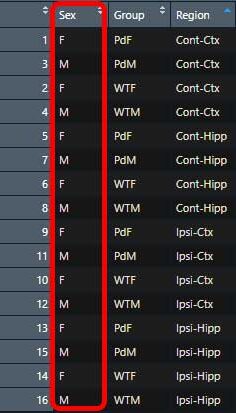
例えば、下記のようなデータで、
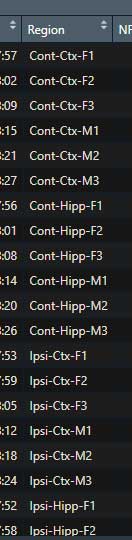
"Region" の列に入っている "Cont-Ctx-F1" etc. の文字列を元にして
- Side: Ipsi or Cont
- Region: Hipp or Ctx
- Sex: M or F
のように、3つの列を作りたい場合。
Side
Side は開始位置1, 終了位置4とする。
mutate(Data, Side = str_sub(Region,1,4))Sex
Sex は、後ろから2番めの記号(F or M)を切り出したいので、開始位置 -2(後ろから数えて2番目), 終了位置 2(後ろから数えて2番目)とする。
mutate(Data, Sex=str_sub(Region,-2,-2)Region
RegionをCtx/Hippの部分のみにしたい場合、Ctx と Hipp は単語の数が違うから、まず4文字取り出して、その後 "gsub" etc. で "-" を削除する。
Dat <- Dat%>%
substring(Region,6,9)
Dat$Region <- gsub("-","",Dat$Region)gsub()の使い方は下記▼
データ整理の続き。 とある csv データを取り込み…… Data1