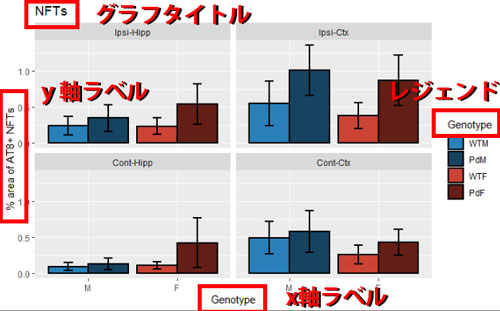
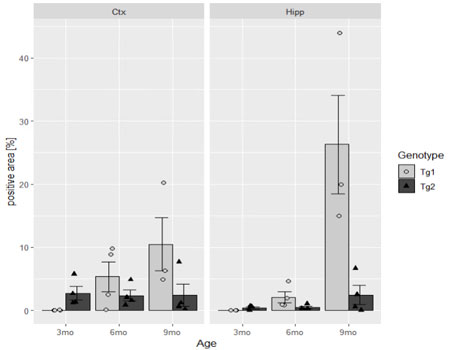
データフレーム内の合計や平均値などを求める時、Rでは「aggregate関数」が用意されているけど、比較的作業時間がかかるため、「dplyr::summarise」の方が良さげ。
ちょっとした集計:dplyr::summarise
全体での平均値を出す場合
例えば、下記テーブル "Data" の "FN" と "NFT" の列の平均値を出したい場合。
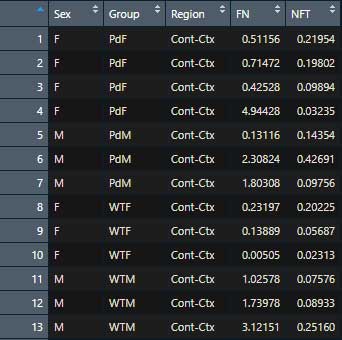
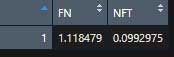
summarise(Data, FN=mean(FN),NFT=mean(NFT))とする。
グループ毎の平均値を出す場合
例えば、上記テーブル "Data" の "FN" と "NFT" の列で、”Sex" と "Group" と ”Region” 毎に平均値を出したい場合。
先に「group_by」でグループを指定してから「summarise」すると良い。
Data %>%
group_by(Data, Sex,Group,Region) %>%
summarise(FN=mean(FN),NFT=mean(NFT))標準偏差(SD)を出す場合
Data %>%
group_by(Sex,Group,Region) %>%
summarise(sd_FN=sd(FN),sd_NFT=sd(NFT))注意事項として、mean や SD のラベルをデータフレームの列のラベルと一緒にしてしまうと、元のラベル名がベクトルではなく1個の値になってしまうので SD が NA になってしまうらしい。
キーワード:tidyverse, dplyr, summarise, mean, sd, NA Rで、平均の折れ線グラフなどを描くときの流れとして library(tidyver...
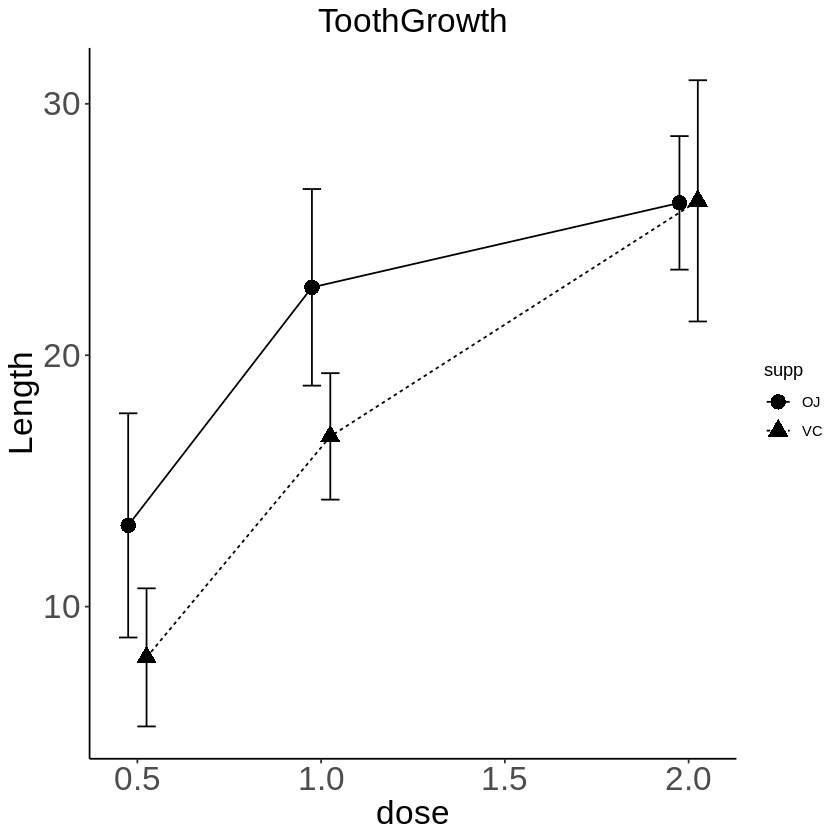
ので、それを避けるために、
- mean のラベルは mean_列名
- SD のラベルは sd_列名
などのように、区別してラベリングするとよい。
もしくは、「across() 」を組み合わせる。
Data %>%
group_by(Sex,Group,Region) %>%
summarise(
across(
NFT,
list(
mean = mean,
sd = sd
)
)
)
リンク
リンク
リンク
リンク