とある csv データを取り込み……
Data1 <- read.csv("Dataset.csv")エクセルのデータを R にインポートする方法。 csv ファイル エクセルデータを csv ファイルに保存してインポートするのが最も一般的。 CSV ファイルとは CSV ファイルは、「comma Separated V …
「str()」で確認すると、
数値になっていてほしいところが、文字列で認識されている。
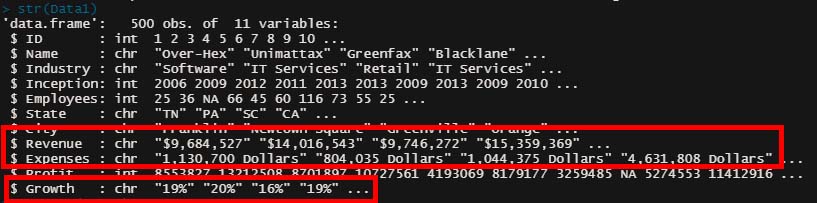
これはなんでかというと、
例えば Revenue や Expenses の行は、3桁毎に「,」で区切られているが、R はこれを「数値」だとは認識せず、「文字列」として認識している。
また、Revenue や Growth の行は、「$」や「%」という文字が入っているので、「文字列」として認識されている。
これらをちゃんと数値として認識させるために、「gsub()」を使って、余計な記号を削除したり置き換えたりする。
gsub()
gsub は、R標準パッケージにある、正規表現のパターンにマッチした文字列を全て置き換える命令文。
正規表現については下記参照 ▼
色々使える正規表現の覚え書き。 正規表現(Regular Expression, Regex)とは 正規表現とは、「いくつかの文字列を一つの形式で表現するための表現方法」。 この形式を使えば、違う言葉etc.が入った文字 …

Rでよく使う正規表現のパターンを、カテゴリー別に整理してみた。 Rで使用する正規表現いろいろ 文字の検索・位置指定に関するパターン パターン 説明 例 ^ 文字列の先頭を指定 ^Hello は "Hello World" …
gsub の使い方は ▼
gsub("置換前の文字","置換後の文字",データ)gsub で「,」を消す
「,」を消したいので、
置換前は「","」、置換後は「""」とすればOK。
Dat$Revenue <- gsub(",","",Data1$Revenue)同様の方法で Expenses の「,」も消す。
Dat$Expenses <- gsub(",","",Data1$Expenses)さらに同様の方法で、Expenses の「Dollars」も消す。
置換前は「"Dollars"」、置換後は「""」とすればOK。
Dat$Exprnses <-gsub("Dollars","",Data1$Expenses)gsub で「$」を消す
Revenue の「$」も消さないといけないけど、この文字はR関数でも使われているので、「文字」だと認識させる必要がある。
文字として認識させる方法は、直前に「\\」をおく。
置換前は「"\\$"」、置換後は「""」とすればOK。
Dat$Revenue <- gsub("\\$","",Data1$Revenue)同様の方法で Growth の「%」も消す。
Dat$Growth <- gsub("\\%","",Data1$Growth)str を確認
以上の作業後にもう一度「str()」で確認すると、
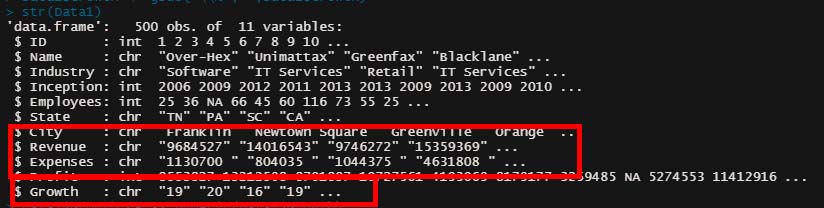
「,」「Dollars」「$」「%」が消えている。
この段階では要素は「Chr:文字列」になっているが、これを「num:数値」に変換する。
Dat$Growth <- as.numeric(Data1$Growth)
Dat$Revenue <- as.numeric(Data1$Revenue)
Dat$Expenses <- as.numeric(Data1$Expenses)数値への変換については下記参照 ▼
これからデータ整理の色々と書き留めていく予定。 まず、とあるcsv データを取り込み。 取り込みの方法は下記 ▼ Data1 is.integer(x) [1] FALSE > is.numeric(x) [1] TRU …
もう一度「str()」で確認すると、
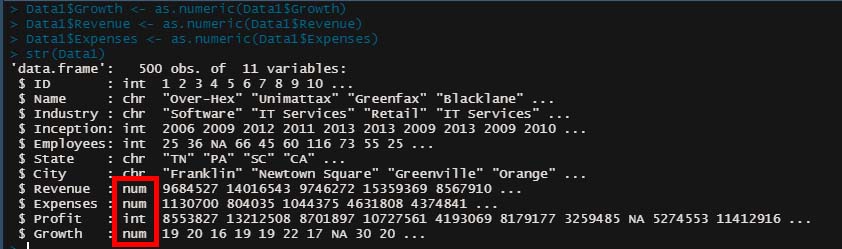
無事数値に変換できた。
sub()
sub()は、gsub()と同じように正規表現に適合した文字列を置換するけど、「1回目に適合した文字列のみを置換する」という点がgsub()と異なる。
例えば、
# Dat
Dat <- c("Apple-Red-Round", "Bananna-Yellow-Long", "Cherry-Magenta-Small")というベクターファイルを作り、
output
[1] "Apple-Red-Round" "Bananna-Yellow-Long" "Cherry-Magenta-Small"
これにsub()で 「-」 → 「,」の置換を指定すると、
sub("-", ",", Dat)それぞれの項目の最初の 「-」のみが 「,」に置換される。
output
[1] "Apple,Red-Round" "Bananna,Yellow-Long" "Cherry,Magenta-Small"
gsub()で 「-」 → 「,」への置換を指定すると、
gsub("-", ",", Dat)全ての 「-」が 「,」に置換される。
output
[1] "Apple,Red,Round" "Bananna,Yellow,Long" "Cherry,Magenta,Small"str_replacement と str_replacement_all
上記R標準パッケージでもいいけど、文字列操作は Hadley氏作製の stringr パッケージが便利。
この関数は、stringrパッケージを読み込んで使用する。
library("stringr")
baseパッケージとstringrパッケージの比較は下記参照。
Rで文字列操作を行う際に、標準パッケージ(baseパッケージ)やstringrパッケージを使っていることが多いと思う。 私の周囲にはstringrを好む人が多いけれども、実際、どちらを使った方がよいのか、調べてみた。 R …
前回、R標準パッケージ(base)とstringrパッケージの比較をしてみて、「処理速度は、場合によってはbase、場合によってはstringrの方が速い」ということがわかった。 で、具体的にどのときにbase、どのとき …
sub()とgsub()に対応する stringr のコードは、
- base::sub -> stringr::str_replace
- base::gsub -> stringr::str_replace_all
使い方は、
str_replace(文字列 (string), 変更前 (pattern), 変更後 (replacement))str_replace_all(文字列 (string), 変更前 (pattern), 変更後 (replacement))のように使用する。
例えば、上記例でstringr::str_replaceを使うと、
# 最初にヒットした単語のみ置換
str_replace(Test,"-",",")output
[1] "Apple,Red-Round" "Bananna,Yellow-Long" "Cherry,Magenta-Small"で、stringr::str_replace_allを使うと、
# 該当する全単語を置換
str_replace_all(Test,"-",",")output
[1] "Apple,Red,Round" "Bananna,Yellow,Long" "Cherry,Magenta,Small"という結果が返ってくる。
References


![]()
![]()

Rで文字列処理をすることって地味によくありますよね。 そんな突如として必要性が湧いてくる文字列処理、Rには文字列を扱うパッケージがいくつかありますが、その中でも抜群に使いやすいのが{stringr}の特徴です。 文字列処理を統一的な方法で行えるため、直感的にも分かりやすく、さらには{dplyr}などのデータフレーム加工パッケージとも相性が良いです。 www.medi-08-data-06.work 今回はそんな{stringr}の使い方をまとめていきます。 文字列の基本処理関数 str_length:文字の長さを調べる str_trim:空白の除去 str_dup:文字の繰り返し str_c:…
