最近リバイスが返ってきて、データ整理に追われ中……
n数を増やす目的等で他から持ってきたデータを結合させた時の備忘録。
dplyr::join
dplyr パッケージの join 関数を使う。
join 関数は4種類。
- full_join
- inner_join
- left_join
- right_join
この中で一番多く使っているのは left_join と full_join
right_join は left_join のデータを入れ替えれば可能なのでほとんど使っていない。
full_join
dplyr::full_joinは、両方のデータの内容を全部残して結合する。
library("dplyr")
full_join("元データ", "結合するデータ", by="参照列名")by = に、IDなどの列名を記載することで、その列で同じ値のデータを結合してくれる。
by = を指定しない、もしくは
by = NULLにすると、同じ列名を全て結合してくれるので、
データが被っていない場合は、
by = NULLにすればOK。
データAとデータBの値が違っていて、全てデータAの値を残したい場合
データAとデータBに違う値がある場合、
by = NULLにすると両方のデータが残る。
例えば下記の場合、23行目 と 24行目 で同じデータが残っているが、それは赤枠で示した部分のデータが "元データ (Data)" と "結合するデータ (Data_Add2) で違っていたから。

今回の場合は、結合するデータに NA 値があり、元データの方の数値を残したいので、"重複行の削除" で上に表示されている元データのみを残す。
重複行の削除 : dplyr::distinct
重複行の削除は、dplyr パッケージの distinct() を使う。
distinct("重複判定する列名", .keep_all=TRUE)distinct() は、重複判定する列名を指定すると、その列で重複するデータは、初出を残して2回目以降を削除する。
- .keep_all = FALSE で、キー項目だけが戻り値となる
- .keep_all = TRUE で、キーでない項目も含めて全項目が戻り値となる。
私が必要なのは全データなので、
.keep_all = TRUEを選択。
もしそこから必要な列のみ取り出したい場合は、パイプで繋いで select() を使用すればOK。
distinct("重複判定する列名", .keep_all=TRUE) %>%
select("取り出したい列名1", "取り出したい列名2")データAとデータBの値が違っていて、列によってどちらを残すか決めたい場合
場合によっては、「列1はデータAを残したいけど、列2はデータBを残したい」というような時もある。
今回は、どちらかのデータが NA で、どちらかのデータに数値が入っているもの想定して進める。
by = "列名" で、参照列を指定
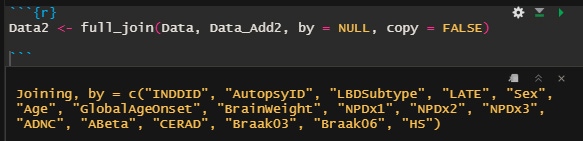
by = "列名" (今回は "INDDID") でデータAとデータBを結合する際の参照列を指定する。
Data2 <- full_join(Data, Data_Add2, by="INDDID", copy=FALSE)
違う値が入っている列は、".x (データA)" と ".y (データB)" という名前で区別される。


どちらかの列に "NA" が入っているけれども、どちらかは列によって異なる場合、
which(is.na(データ$列名))と
!is.na(データ$列名)で、NA のあるデータを割り出し、数値のある方のデータに置換する。
which(is.na(Data2$NPDx3.x) & !is.na(Data2$NPDx3.y)) Data2$NPDx3.x[z] <- Data2$NPDx3.y[z]
dplyr::rename(Data2, NPDx3=NPDx3.x) -> Data2
z <- which(is.na(Data2$ADNC.y) & !is.na(Data2$ADNC.x)) Data2$ADNC.y[z] <- Data2$ADNC.x[z]
dplyr::rename(Data2, ADNC=ADNC.y) -> Data2
z <- which(is.na(Data2$ABeta.x) & !is.na(Data2$ABeta.y)) Data2$ABeta.x[z] <- Data2$ABeta.y[z] dplyr::rename(Data2,
ABeta=ABeta.x) -> Data2その後、
dplyr::renameで、.x か .y を削除する。
下記は、全部 .x のデータに置き換えて、.y の列を削除する場合 (データ名を変えて、随時保存しておくのが良い。)▼
Data3 <- select(Data2, -(ends_with(".y")))left_join
dplyr::left_joinは、左側にある元データに、新たなデータを結合する。
library("dplyr")
left_join("元データ", "結合するデータ", by="参照列名")by = に、IDなどの列名を記載することで、その列で同じ値のデータを結合してくれる。
by = を指定しない、もしくは
by = NULLにすると、同じ列名を全て結合する。
元データA と 結合データB が、ID とかだけ共通でそれ以外は違う項目だった場合は、
by = "ID"にして left_join すればOK。
気をつけるべきは、結合後のデータは元データが基本となっている、ということ。
例えば元データA の行数が結合データB の行数よりも少ない場合、
元データA に存在している行のみが結合後にされ、データB にあってデータA にない行は削除される。
また、元データA と結合データB の値が違う場合は、データA の値が反映される。
inner_join
dplyr::inner_joinは、元データA と結合データB で共通する行だけを残す。
library("dplyr")
inner_join("元データ", "結合するデータ", by="参照列名")by = に、IDなどの列名を記載することで、その列で同じ値のデータを結合してくれる。
References
マーケター1年目の小幡さんがRを学んでいきます。講師は株式会社ヴァリューズのデータアナリスト、輿石さん。第6回はRを使ったデータ同士を結合させるjoin関数を習得します。Rでデータを扱えるようになりたいと考えている方、ぜひ小幡さんと一緒に勉強していきましょう。

SQLの select distinct では指定した列をキーにして重複のないデータを取得できます。 重複する行を削除するSELECT DISTINCT - 一所懸命に手抜きする 重複行削除の際、重複判定に指定したキー列項目以外の列も取得するSQL - 一所懸命に手抜きする R言語でも同様のことができるのは既に書きました。 R言語のuniqueや!duplicated で重複のないデータを取り出す - 一所懸命に手抜きする dplyrパッケージを使うと、もっと簡単に実現できます。 Sampleデータ作成 当ブロクで使うサンプルデータを作成するコード保管庫|R|一所懸命に手抜きする[忍者] に掲…