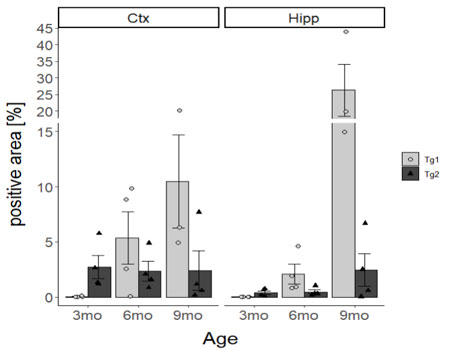
下記のようなデータフレーム(df)があり、行を昇順or降順で並べ替えたい時。

私が使いやすいと思う順で
arrange(),
order,
sort()の使い方を書き留めておく。
dplyr::arrange() 関数
arrange()はdplyrのパッケージの中に入っている。
install.packages("dplyr")
library(dplyr)昇順で並べ替え
方法は、
arrange(データ名, 参照する列。
df2 <- arrange(df, CSF_tTau)行が"CSF_tTau"の列の値の昇順で並べ替えられた。

降順で並べ替え
降順での並び替えは、
desc()を追加する。
df2 <- arrange(df, desc(CSF_tTau))今度は、CSF_tTauの値を参照にして行が降順並び替えられた。

文字列で並び替え
例えば下記のデータ。
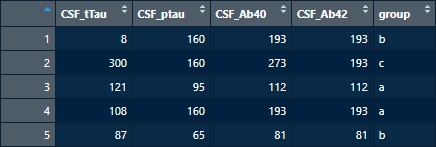
"group" の列の文字列 "a", "b", "c"でソートしたい場合は、そのベクターをfactorに変換して、levelsを指定すればOK。
factor(df7$group, labels = c("a", "b", "c"))
df8 <- arrange(df7, df7$group)
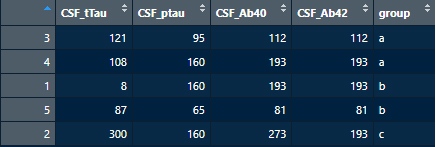
降順は
desc()をつける。
df9 <- arrange(df7, desc(group))
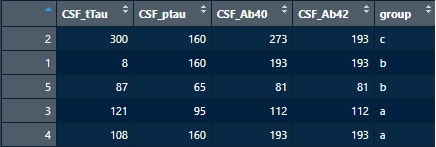
複数列の条件で並び替え
by_group = TRUEにすると、指定した列のグループごとで列を並び替える。
下記データを、
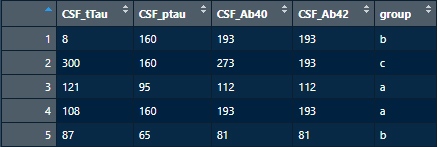
"group" の記号 "a", "b", "c" 毎に、CSF_tTauの値を昇順でソートしたい場合。
<code="language-r">df2 <- arrange(df, desc = FALSE, .by_group = TRUE
下記の様にグループ a, b, c で分かれてCSF_tTauの値で昇順でソートされた。
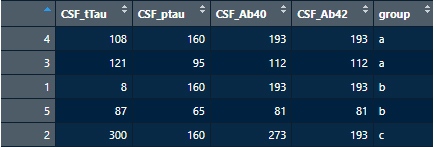
order() 関数
R標準パッケージの
order()を使う方法。
order関数は、引数の項目でソートしたときに元データの項目番号がどういう順番で並ぶかを返してくれる。
rank関数がデータを昇順で並べた時のソート後の順番を返すのと違う点に注意。
先日、共著者から送られたデータの中に、下記のようなコードがありました。 model
昇順で並び替え
order関数をデータフレームの任意の列に適応すると、結果がベクターで返ってくる。
> df2$CSF_tTau
[1] 121 87 208
> order(df2$CSF_tTau)
[1] 2 1 3この結果を元のデータフレームの行部分に充てると、その順番で並べ替えられたデータが返ってくる。
降順で並び替え
データを降順でソートしたい時は、
decreasing = TRUEで指示する。
df4 <- df2[order(df2$CSF_tTau, decreasing=T),]文字列で並び替え
文字列をfactorにしてlevelsを指定すれば、その順番でも並び替え可能。
例えば下記データがあって、
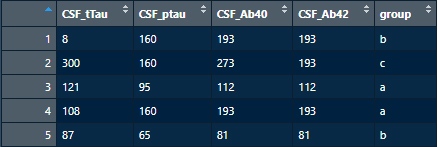
"a", "b", "c" の順で行を並び替えたい場合。
factor(df7$group, labels = c("a", "b", "c"))
df8 <- df7[order(df7$group), ]
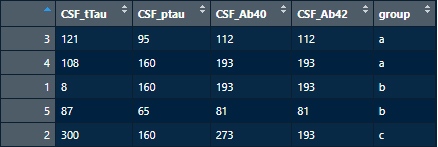
複数列の条件で並び替え
条件列は複数でもOK。
df9 <- df7[order(df7$group, df7$CSF_tTau), ]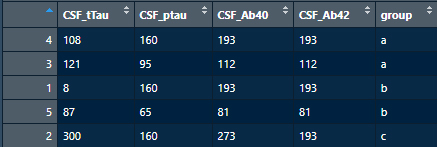
sort() 関数
R標準パッケージの
sort()関数でもデータフレームの行を並び替える事ができる。
例えば、下記のようなデータがあったとする。
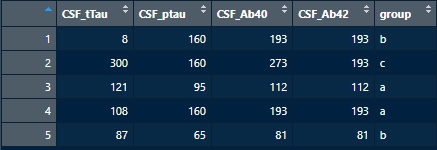
昇順で並び替え
sort()関数は、ベクトルの要素を昇順で並び替える。
> sort(df7$CSF_tTau)
[1] "108" "121" "300" "8" "87"
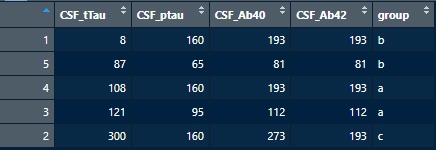
けれども、ベクトルの要素を返すため、sort関数の結果のみでデータセット全体を並び替える事はできず、結果とその行番号を返す引数 "index" を指定し、並び替え後の行番号を格納する "$ix" を使う。
df10 <- df7[sort(df7$CSF_tTau, index=T)$ix,]
降順で並び替え
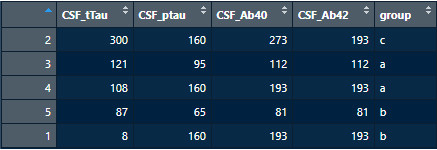
降順にしたい場合は、
decreasing = TRUEを指定する。
df11 <- df7[sort(df7$CSF_tTau, decreasing=T, index=T)$ix,]
References
tidyverseで1つのデータフレームに対する行のソートは、dplyrパッケージのarrange関数を使います。arrange関数は、データフレームの行をソートする関数です。エクセルの行の並べ替えのように、優先度の高いものから複数の条件を
arrange() orders the rows of a data frame by the values of selected columns. Unlike other dplyr verbs, arrange() largely ignores grouping; you need to explicitly mention grouping variables (or use .by_group = TRUE) in order to group by them, and functions of variables are evaluated once per data frame, not once per group.
次のタスクを実行するための良い方法は何ですか? たとえば、データフレームがあります。 v2 - c4.5, 2.5, 3.5, 5.5, 7.5, 6.5, 2.5, 1.5, 3.5 v1 - c2.2,
1.この記事の目的 データ分析では、分析の目的に応じて、データセットから特定のデータを抽出し、特定の統計処理を行うことが頻繁にあります。 <具体例> ①体重の上位100人と下位100人の血圧の平均値を比較 ②人口の上位10地区と下位10地区で所得の中央値を比較 ③資本金の上位50社と下位50社に分けて線形回帰を実施 こうした具体例を実践するには、平均値や中央値、線形モデルの推定等の統計処理を行う前に、以下のステップを必要があります。 <統計処理に至るまでのステップ> ①抽出の前準備 :特定の変数を基準にデータセットを並び替える。 ②データの抽出 :基