例えば、下記のようなデータがあって、
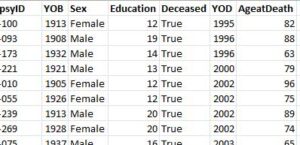
"Deceased" が "True" と "False" と入力されている症例がそれぞれどれくらいずつあるか知りたい時。
count(group_by())で求める。
Dat1 <- read_xlsx("./Data/test.xlsx") %>%
rename(OldestCDR = 'oldest CDR') %>% # 列名を "Oldest CDR" から "OldestCDR"に変更
filter(complete.cases(Dat1$OldestCDR)) # OldestCDRの列の値がNAになっている物を削除
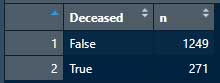
Dat2 <- count(group_by(Dat1, Deceased)) # Deceasedでグルーピングして、それぞれ "True" と "False" が何人ずついるかDat3 を見ると、Trueが271人、Falseが1249人だった。
リンク
リンク
リンク
リンク
