NAの取り扱いシリーズ第4段。
今回は、他のデータから推測して補完する方法。
よく使われるのは、中央値(median)で補完する方法。
場合によっては平均値(mean)でもいいけど、中央値の方が外れ値の影響を受けにくいので、中央値の方が好まれる。
群の中央値で補完 (1)
例えば下記のようなデータフレーム(Dat)で、"Employees" のデータが2箇所欠損している。
# NA値のある行を全部抽出
Dat[!complete.cases(Dat), ]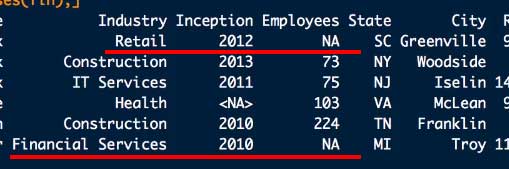
補完したい欠損値のみ抽出
!complete.cases()だと、NA値のあるデータを全て抽出してくるけど、今回は "Employees" にNA値がある行だけを選択したいので、
# "Employees" がNAのデータを抽出
Dat[!complete.cases(Dat$Employees), ]
Industry の列を見ると、
- Retail
- Financial Services
と異なっている。
両方とも全体の中央値で補完してもいいけど、異なる Industry では Employees の数も違うはず。
なので、
- "Retail" の "Employees" は "Retail" の中央値で
- "Financial Services" の "Employees" は "Financial Services" の中央値で
補完した方が、より現実的な値に近くなるはず。
とゆーことで、まずは "Industry" が "Retail" & "Industry" が "NA" の行を抽出。
# "Employees" がNAで、"Industry" が "Retail" のデータを抽出
Dat[is.na(Dat$Employees) & Dat$Industry=="Retail", ]
群の中央値の求め方
"Employees"の列全体の中央値なら、
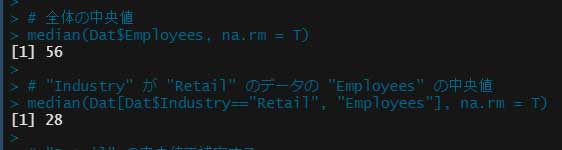
# 全体の中央値
median(Dat$Employees, na.rm = T)で求められる。
median(Dat$Employees)だけにすると、"NA" 値を含む列は全て "NA" で返ってしまうので、
na.rm = Tで「NA値を除く」と指定しておく。
"Industry" が "Retail" の行の "Employees" の中央値は、下記で出す。
# "Industry" が "Retail" のデータの "Employees" の中央値
median(Dat[Dat$Industry=="Retail", "Employees"], na.rm = T)
全体の "Employees" の中央値は "56"、"Industry" が "Retail" の行の "Employees" の中央値は、"28" という結果が返ってきた。
欠損値の部分に群の中央値を入れる
最初に出していた "Industry" が "Retail" & "Industry" が "NA" の行を抽出。
# "Employees" がNAで、"Industry" が "Retail" のデータを抽出
Dat[is.na(Dat$Employees) & Dat$Industry=="Retail", ]で、ここの "Employees" の列に "群の中央値: 28" を入れたいので、
# "Retail" の中央値で補完する
Dat[!complete.cases(Dat$Employees & Dat$Industry=="Retail"), "Employees"] <- median(Dat[Dat$Industry=="Retail", "Employees"], na.rm=T)
これで補完されたのだけれど、画面上に現れるわけではないので、該当する行(今回は3行目)を抽出して確認してみると、
# 確認
Dat[3,]ちゃんと挿入されてた。
群の中央値で補完する(2)
中央値で補完はいいけど、より正確に計算できる場合はその計算によって求めた方がいい。
例えば、下記データフレーム(Dat)で、"Expenses" の値を補完しようと思うけど、

17行目の "Expenses" は、両隣の "Revenue" と "Profit" から計算できる。
なので、
- 他の方法で計算可能な行を除いて NA行を抽出
- 群ごとに中央値を求めて代入
という方法をとる。
# Dat$Profit が NA じゃないデータを抽出
Dat[!complete.cases(Dat) & is.na(Dat$Profit),]すると、8行目と44行目のデータのみが抽出された。

で、ver.1のときと同じように、それぞれのIndustryの中央値で補完する。
今回は両方とも "Construction" なので、
# "Industry" が "Construction" の列の中央値を算出
median(Dat[Dat$Industry=="Construction","Expenses"], na.rm = TRUE)"4506976" という値が返ってきた。

これを、最初に抽出した NA のデータに代入する。
# "Industry" が "Construction" の列の中央値を算出
Construction_Expenses_median <- median(Dat[Dat$Industry=="Construction" ,"Expenses"], na.rm=TRUE)
Dat[!complete.cases(Dat) & is.na(Dat$Profit),"Expenses"] <- Construction_Expenses_medianちゃんと代入されたか、8行目と44行目のデータを確認してみる。
# 確認
Dat[c(8,44),]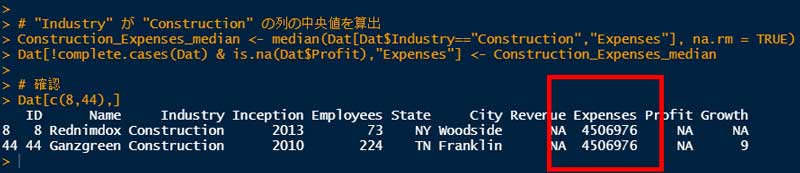
ちゃんと代入されていた。

References


![]()
![]()