NAの取り扱いシリーズ第2段。
今回は、NAがある行を取り除いて解析する方法。
NAのある行を抽出
まずは、前回のおさらい。
全体でNAがある行を抽出する方法。
Dat[!complete.cases(Dat),]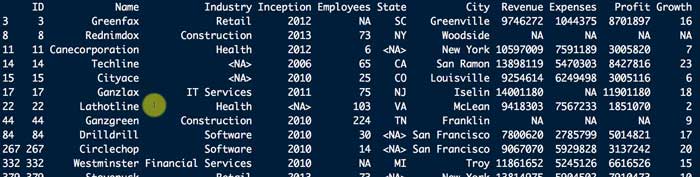
で、例えば "Industry" の列に欠損値がある行を選出する方法。
Dat[is.na(Dat$Industry),]すると、"Industry" 列が<NA>の14行と15行が抽出された。

NAのある行を除いたデータを抽出
上記Dat[is.na(Dat$Industry),]を逆にすれば、NAがない行を抽出できる。
Dat <- Dat[!is.na(Dat&Industry),]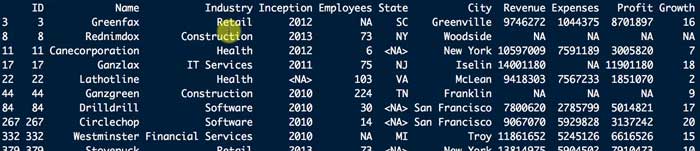
レコードを削除した後にデータフレームの番号をリセットする
上記の方法でNAのある行を削除すると、その部分の番号が飛ばされて並ぶことになる。
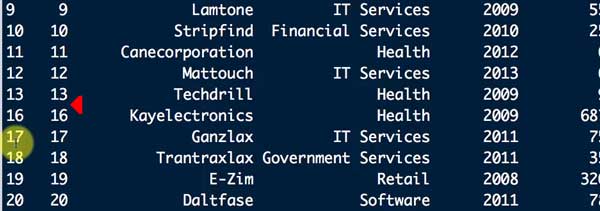
データ解析法によってはそのままにしておく方が良い時もあるけど、データのサンプル数とか簡単に把握できるようにしておきたいとか、色々な目的でデータフレームのインデックスをリセットしたい時がある。
そんな時の方法2選。
これを修正するためには、
rownames()を使う。
rownames() <- 1:nrow()
データのrownamesを、1からrownameの数(1:nrow())として指定するとOK。
rownames(Dat) <- 1:rnow(Dat)列の番号が1から順番にあてがわれ、最終行は除外した2行分だけ少ない "498" になった。
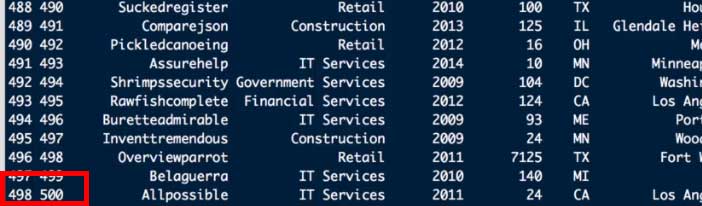
rownames() <- NULL
NULLでリセットしてもOK。
rownames(Dat) <- NULL番号がリセットされて、最終行は2行分抜いた "498" になった。
References


![]()
![]()
リンク
リンク
リンク
リンク