列A、列B、列C...の各行毎に平均値を出して、それぞれ新しい列に結果を追加する方法3つ。
個人の練習も兼ねて前後の工程も記載しているので、あしからず。
事前準備
データの取り込み
人からもらった、とあるデータを取り込む。
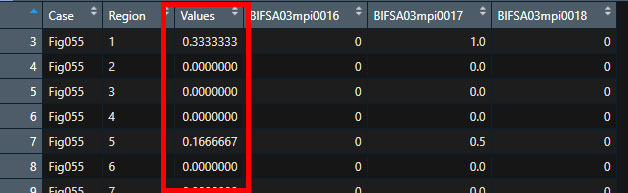
Dat1 <- read.csv("./Data/Fig055.csv", header=TRUE)結果は下記。
データのチェック
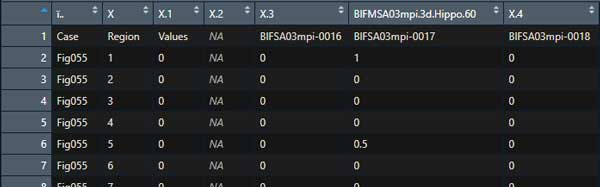
取り込んだデータの5-7列にある各行の数値の平均値を3行目のvaluesい入れたいんだけど、このままだと色々困る。
列名になってほしい行がなぜか1行目にきてデータの一部として認識されているし、
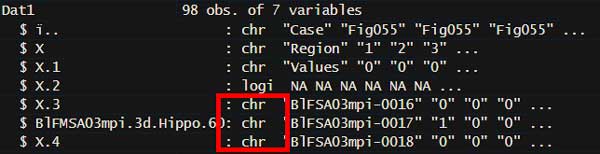
strをみてみると、平均値を出したい5-7列目のデータ型が全て "character" になっている(……ので計算できない)。
目的の行を "colnames" に変更
データを取り込むときに、
header=TRUEに設定して取り込んだから、1行目は colnames となっている予定だったのに、なんか変。
colnames になるべき行はデータの1行目になっている。
「?」と思って元データをみると、
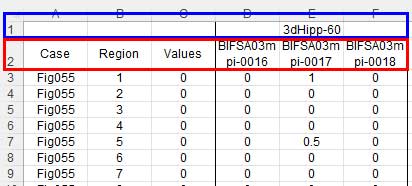
行名が2行に分かれていて、E1にある"3dHipp-60"のセルを含む1行目(青枠)が colnames に宛てがわれ、本来 colnames に宛てがいたい2行目(赤枠)がデータの1行目として認識されていた。
この "3dHipp-60" は要らないので、まず1行目を消し、その後1行目となった赤枠を colnames に指定する。
そのためには、まずデータを
header=FALSEで読み込む。
Dat1 <- read.csv("./Data/Fig055.csv", header=FALSE)で、1行目を削除し、ついでに "NA" 列になっている4列目も要らないので削除。
Dat1 <- Dat1[-1,-4]その後、1行目に繰り上がった赤枠行を colnames に指定。
colnames(Dat1) <- Dat1[1,]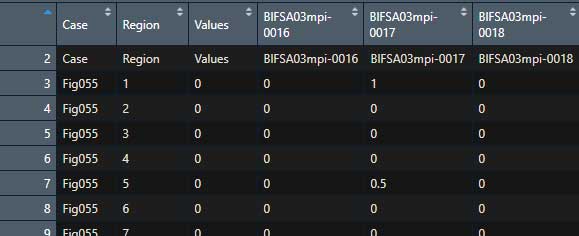
1行目に名前の行が残ったままなので、これを削除し、
ついでにハイフンのある名前達をハイフン無しに変更(ハイフンがあると色々面倒なので)。
Dat1 <- Dat1[-1,] %>%
rename(BlFSA03mpi0016 = "BlFSA03mpi-0016",
BlFSA03mpi0017 = "BlFSA03mpi-0017",
BlFSA03mpi0018 = "BlFSA03mpi-0018")目的の行が colnames になり、余計な行列が削除されたデータができあがった。
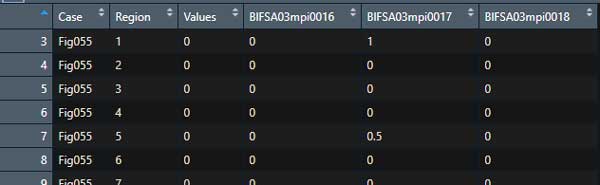
目的の列を "numeric" に変更
で、平均値を出したい列(BlFSA03mpi0016, BlFSA03mpi0017, BlFSA03mpi0018)のデータ型を "numeric" に変更。
Dat1$BlFSA03mpi0016 <- as.numeric(Dat1$BlFSA03mpi0016)
Dat1$BlFSA03mpi0017 <- as.numeric(Dat1$BlFSA03mpi0017)
Dat1$BlFSA03mpi0018 <- as.numeric(Dat1$BlFSA03mpi0018)str()で"numeric" に変更されていることを確認。
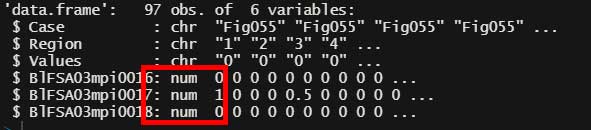
各行の平均値の列を追加
データが綺麗になった所で、目的の「各行の平均値を示す列を追加」の作業に取り掛かる。
ここでは3つの方法を書き留めておく。
方法1: rowMeans
方法の1つ目は、
rowMeanasを使う方法。
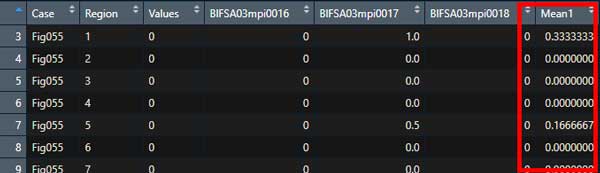
上記データフレームの4行目から6行目の平均値を入れた列(列名: Mean1)を作ってみる。
Dat1 <- Dat1 %>%
mutate(Mean1 = rowMeans(.[,4:6]))データフレームの右側に、4-6列目の平均値が入った "Mean1" の列が追加された。
方法2: rowwise
方法の2つ目は、
rowwiseを使う方法。
上記と同じ様に
dyplr::mutateで、4-6列目の各行の平均値を入れたいんだけど、
普通に
mean()を使うと、「列の平均」を計算してしまうので、
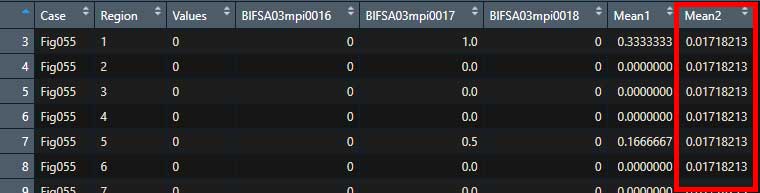
Dat1 <- Dat1 %>%
mutate(Mean2 = mean(c(BlFSA03mpi0016,BlFSA03mpi0017,BlFSA03mpi0018)))こんな感じに1列の平均値が全セルに適応されてしまう。
これを「行の平均値」に変えたい場合は、その前に
rowwise()をはさんであげると良い。
Dat1 <- Dat1 %>%
rowwise() %>%
mutate(Mean2 = mean(c(BlFSA03mpi0016,BlFSA03mpi0017,BlFSA03mpi0018)))
上記データフレームの4行目から6行目の平均値を入れた列(列名: Mean2)を作ってみる。
Dat1 <- Dat1 %>%
mutate(Mean1 = rowMeans(.[,4:6]))データフレームの右側に、4-6行目の平均値が入った "Mean2" の列が追加された。
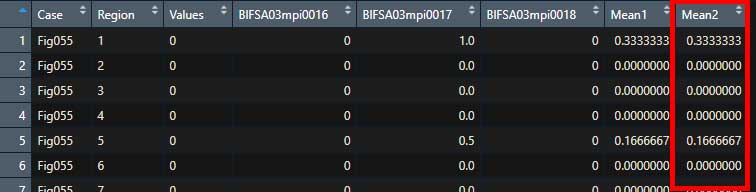
ちゃんとした値が入ってくれた。
方法3:apply関数
apply関数は、Rの標準パッケージに組み込まれている。
apply の他、tapply, lapply, sapply, mapply などがある。
apply 関数は、データフレームの行もしくは列毎に計算して値を出したい場合に使う。
例えば今回は、上記データフレームの4列目から6列目の平均値を出したいので、コードはこんな感じ。
apply(Dat1[,4:6], 1, mean, na.rm=TRUE)na.rm=TRUEと設定すれば、NAを飛ばして計算してくれる。
第2因数は、
- 1→ 横方向に計算(1行毎にまとめて関数に渡して処理)
- 2→ 縦方向に計算(1列毎にまとめて関数に渡して処理)
というように指定する。
mutate()で新たな列に追加したい場合は、
Dat1 <- Dat1 %>%
mutate(mean3 = apply(Dat1[,4:6], 1, mean, na.rm=TRUE))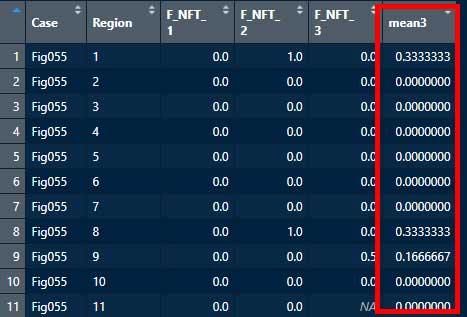
無事に平均値の入った列が追加された。
各行の平均値を既存の列に上書き
上記のように算出したデータ、本来は新しい列ではなく、"Values" の列に適応したかったので、
mutate()の列名の所を "Values" にする。
Dat1 <- Dat1 %>%
mutate(Values = rowMeans(.[,4:6]))無事 "Values" の列に上書きされた。