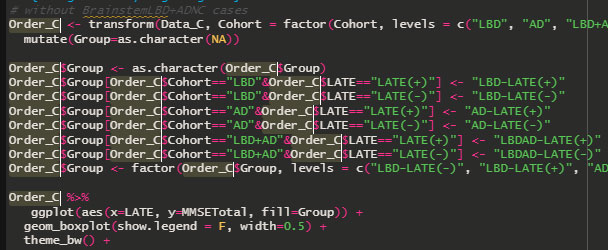
下記のようなデータがあって、
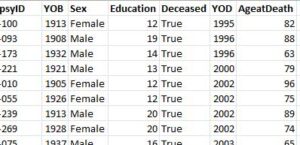
"Deceased" が "True" と "False" と入力されている症例がそれぞれどれくらいずつあるか count(group_by())
で求めると、
Dat1 <- read_xlsx("./Data/test.xlsx") %>%
rename(OldestCDR = 'oldest CDR') %>% # 列名を "Oldest CDR" から "OldestCDR"に変更
filter(complete.cases(Dat1$OldestCDR)) # OldestCDRの列の値がNAになっている物を削除
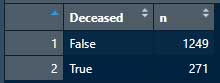
Dat2 <- count(group_by(Dat1, Deceased)) # Deceasedでグルーピングして、それぞれ "True" と "False" が何人ずついるかTrueが271人、Falseが1249人だった。
ここで、INDDIDの項目に重複する行がある事に気づいたので、dplyr::distinct()で重複行を削除した。
Dat1 <- read_xlsx("./Data/test.xlsx", sheet = 'test') %>% #データのインポート、エクセルファイルの'test'タブ
rename(OldestCDR = 'oldest CDR') %>% # 'oldest CDR' の列名を 'OldestCDR' に変更
filter(complete.cases(OldestCDR)) # 'OldestCDR' の中に値が入っているもののみ抽出
Dat2 <- distinct(Dat1, INDDID, .keep_all = TRUE) # INDDID の行内で重複する項目を削除。.keep_all = TRUEで他の項目も残す
Dat2 <- count(group_by(Dat2, Deceased)) # 'Deceased' の項目で 'True' と 'False' がそれぞれ何人いるか- .keep_all を TRUE にすると、該当列(ここではINDDID)以外の列も残す。
- .keep_all を FALSE にすると、該当列以外の列は削除される。
・
・
・
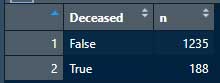
重複した項目を削除したため、カウント結果はTrueが188人、Falseが1235人になった。
リンク
リンク
リンク
リンク